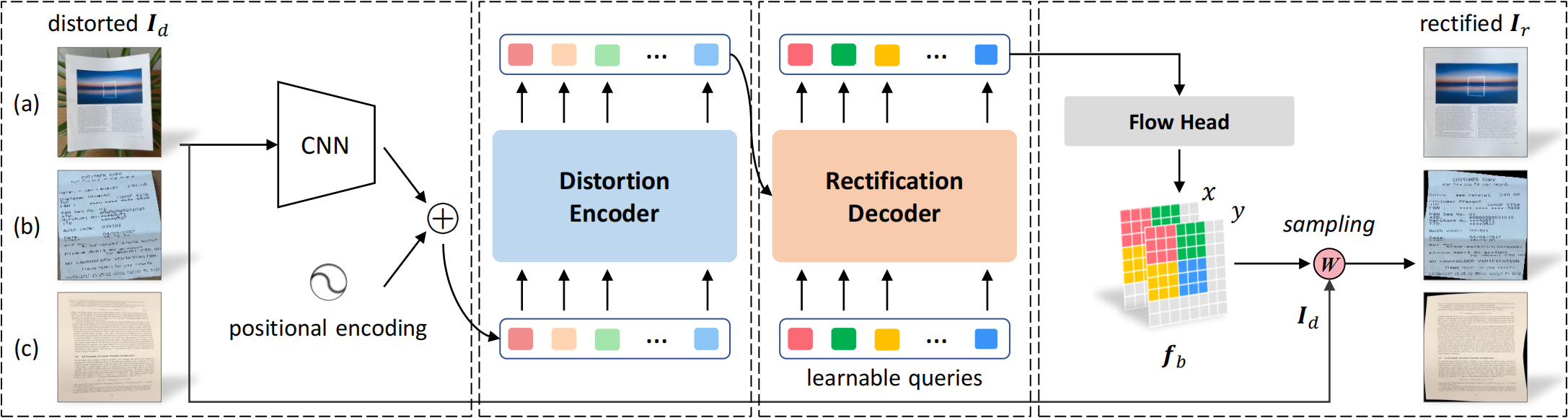
Unrestricted Rectification
Top row: three types of commonly distorted document images based on the presence of document boundaries:
(a) w/ complete boundaries,
(b) w/ partial boundaries,
(c) w/o any boundaries.
Middle row: the rectified results of our method.
Bottom row: the distorted image, the original detected texts, and the rectified one (highlighted), based on DBNet.


